數(shù)據(jù)預(yù)處理的核心流程與關(guān)鍵步驟解析
數(shù)據(jù)預(yù)處理是數(shù)據(jù)分析與挖掘的基石,其質(zhì)量直接決定了后續(xù)模型的性能與結(jié)果的可靠性。一個完整的數(shù)據(jù)預(yù)處理流程旨在將原始、雜亂、不完整的數(shù)據(jù)轉(zhuǎn)化為干凈、一致、適用于分析的標(biāo)準(zhǔn)化數(shù)據(jù)集。通常,數(shù)據(jù)預(yù)處理包含以下幾個核心流程:
1. 數(shù)據(jù)收集與獲取
這是流程的起點(diǎn)。數(shù)據(jù)可能來自數(shù)據(jù)庫、API接口、日志文件、傳感器、調(diào)查問卷等多種異構(gòu)源。明確分析目標(biāo),并據(jù)此收集相關(guān)數(shù)據(jù)是第一步。
2. 數(shù)據(jù)清洗
這是預(yù)處理中最關(guān)鍵、最耗時的環(huán)節(jié),旨在處理數(shù)據(jù)中的“臟數(shù)據(jù)”。主要包括:
- 處理缺失值:根據(jù)情況選擇刪除缺失記錄、用均值/中位數(shù)/眾數(shù)填充,或使用插值、模型預(yù)測等更復(fù)雜的方法。
- 處理異常值:識別并處理偏離正常范圍的數(shù)值。可通過箱線圖、3σ原則等方法檢測,并根據(jù)業(yè)務(wù)邏輯決定是修正、刪除還是保留。
- 糾正不一致數(shù)據(jù):統(tǒng)一格式、單位、編碼(例如將“男/女”統(tǒng)一為“M/F”),解決拼寫錯誤和重復(fù)記錄。
3. 數(shù)據(jù)集成與轉(zhuǎn)換
數(shù)據(jù)集成:將來自多個數(shù)據(jù)源的數(shù)據(jù)合并,形成一個一致的數(shù)據(jù)存儲。需處理實(shí)體識別、屬性冗余和值沖突等問題。
數(shù)據(jù)轉(zhuǎn)換:將數(shù)據(jù)轉(zhuǎn)換為適合建模的形式。常見操作包括:
* 規(guī)范化/標(biāo)準(zhǔn)化:消除不同特征間的量綱影響,如最小-最大規(guī)范化、Z-score標(biāo)準(zhǔn)化。
- 數(shù)據(jù)離散化:將連續(xù)數(shù)據(jù)分段為分類數(shù)據(jù)(如年齡分段為“青年”、“中年”)。
- 特征構(gòu)造:基于現(xiàn)有特征創(chuàng)建新的、更具預(yù)測能力的特征(如從日期中提取“星期幾”、“是否節(jié)假日”)。
4. 數(shù)據(jù)歸約與降維
在盡可能保持?jǐn)?shù)據(jù)原貌的前提下,降低數(shù)據(jù)規(guī)模,提升處理效率。方法包括:
- 特征選擇:從原始特征中篩選出最相關(guān)、最重要的子集。
- 維度約減:使用主成分分析(PCA)等方法,將高維數(shù)據(jù)投影到低維空間。
- 數(shù)據(jù)抽樣:在數(shù)據(jù)量極大時,使用有效的抽樣方法獲得代表性樣本。
5. 數(shù)據(jù)格式化與存儲
將處理好的數(shù)據(jù)轉(zhuǎn)換為最終分析系統(tǒng)或模型所需的特定格式(如CSV、數(shù)據(jù)庫表、特定框架的Tensor等),并進(jìn)行持久化存儲,供后續(xù)階段直接調(diào)用。
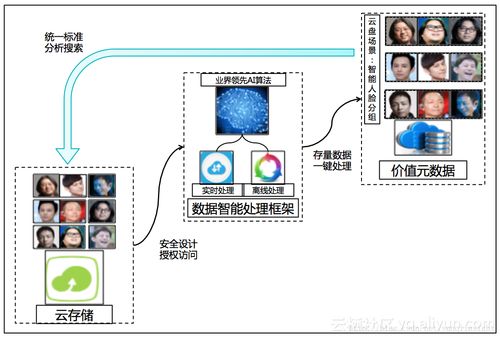
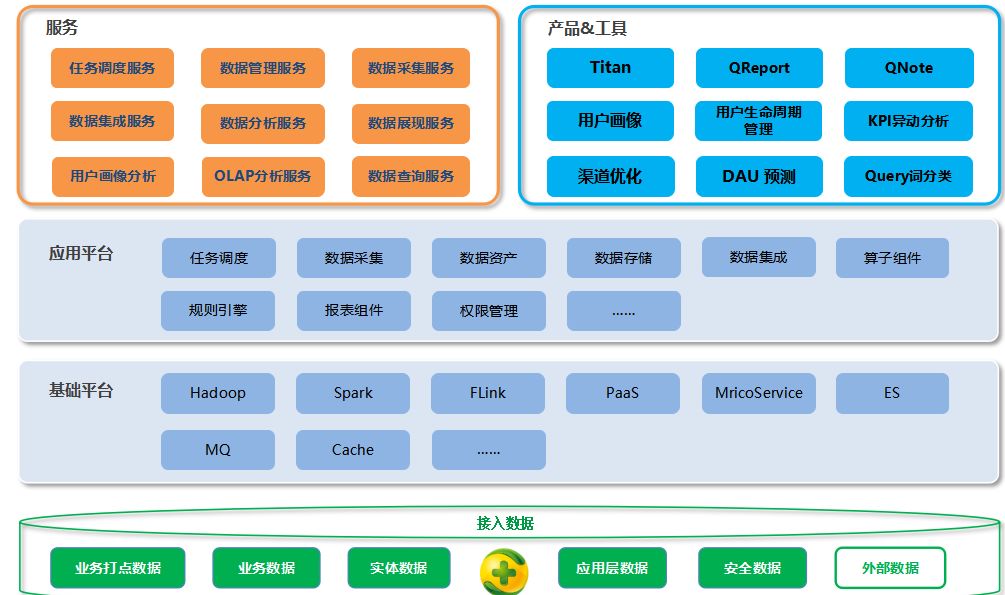
而言,數(shù)據(jù)預(yù)處理是一個系統(tǒng)性的工程,各步驟之間并非完全線性,可能需要迭代進(jìn)行。以億信華辰等專業(yè)數(shù)據(jù)服務(wù)商提供的數(shù)據(jù)處理服務(wù)為例,其價值在于能夠借助成熟的平臺和專家經(jīng)驗(yàn),將上述流程自動化、標(biāo)準(zhǔn)化和規(guī)模化,確保數(shù)據(jù)在進(jìn)入核心分析或應(yīng)用前的“健康度”,從而為數(shù)據(jù)驅(qū)動決策奠定堅(jiān)實(shí)基礎(chǔ)。
如若轉(zhuǎn)載,請注明出處:http://www.nylijie.cn/product/54.html
更新時間:2026-01-23 13:58:06